原文:
www.kdnuggets.com/2020/08/implementing-mlops-edge-device.html
评论
作者:Felix Baum,高通技术公司
传统软件的生命周期可以说相当直接。最简单来说,你开发、测试和部署软件,然后根据需要发布带有新功能、更新和/或修复的新版本。为了便于此,传统软件开发通常依赖于DevOps,它涉及持续集成(CI)、持续交付(CD)和持续测试(CT),以减少开发时间,同时持续交付新版本并维护质量。
 1. Google 网络安全证书 - 快速开启网络安全职业生涯。
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
在机器学习(ML)建模中,人们很容易认为 ML 工作流遵循类似的模式。毕竟,这应该只是创建和训练 ML 模型、部署它,并根据需要发布新版本的问题。但 ML 系统运行的环境使事情变得复杂。首先,由于数据驱动的、非确定性的行为,ML 系统本质上与传统软件不同。而且,正如近期全球事件所突显的那样,我们的世界在不断变化,因此 ML 从业者必须预见到生产模型所推断的真实数据也必然会发生变化。
因此,出现了一种特殊的 ML DevOps,称为MLOps(“机器学习与运维”的缩写),以帮助管理这种持续变化和随之而来的模型重新部署需求。MLOps 继承了 DevOps 的持续集成和持续交付,但将持续测试阶段替换为持续训练。这种新模型的持续训练,包括这些新模型的重新部署及其相关的所有技术工作,旨在解决 ML 项目的三个显著方面:
-
对于模型如何以及为什么做出某些预测的“可解释性”的需求。这对审计目的尤其重要,以满足法规和/或某些预测性能水平。
-
模型衰退,即由于模型遇到的新变化的真实世界数据导致生产模型的预测性能随时间下降。
-
模型的持续开发和改进是由业务需求驱动的。
持续训练,实际上,MLOps 一般都接受模型会不断且不可避免地变化的理念,这意味着组织在不同程度上实施 MLOps 策略和战术。
随着 MLOps 的发展,许多组织提出了最佳实践框架。一个突出的例子是 谷歌的 MLOps 指南,它描述了组织采用的三种 MLOps 实现级别:
-
MLOps 级别 0: 手动过程:模型训练和部署的需求被正式认可,但通常是手动执行的,往往通过脚本和交互过程以临时方式进行。这一层级通常缺乏持续集成和持续交付。
-
MLOps 级别 1: ML 流水线自动化:这一层级引入了一个持续训练的流水线。数据和模型验证是自动化的,并且设置了触发器,以便在模型性能下降时用新数据重新训练模型。
-
MLOps 级别 2: CI/CD 流水线自动化:ML 工作流程已经自动化到数据科学家可以在减少开发人员干预的情况下更新模型和流水线的程度。
实施了 MLOps 级别 2 或 MLOps 级别 3 的组织可能还会使用所谓的“影子模型”,这些模型与生产模型并行训练,每个模型使用不同的训练数据集。当需要新的生产模型时,可以快速选择和部署一个影子模型。
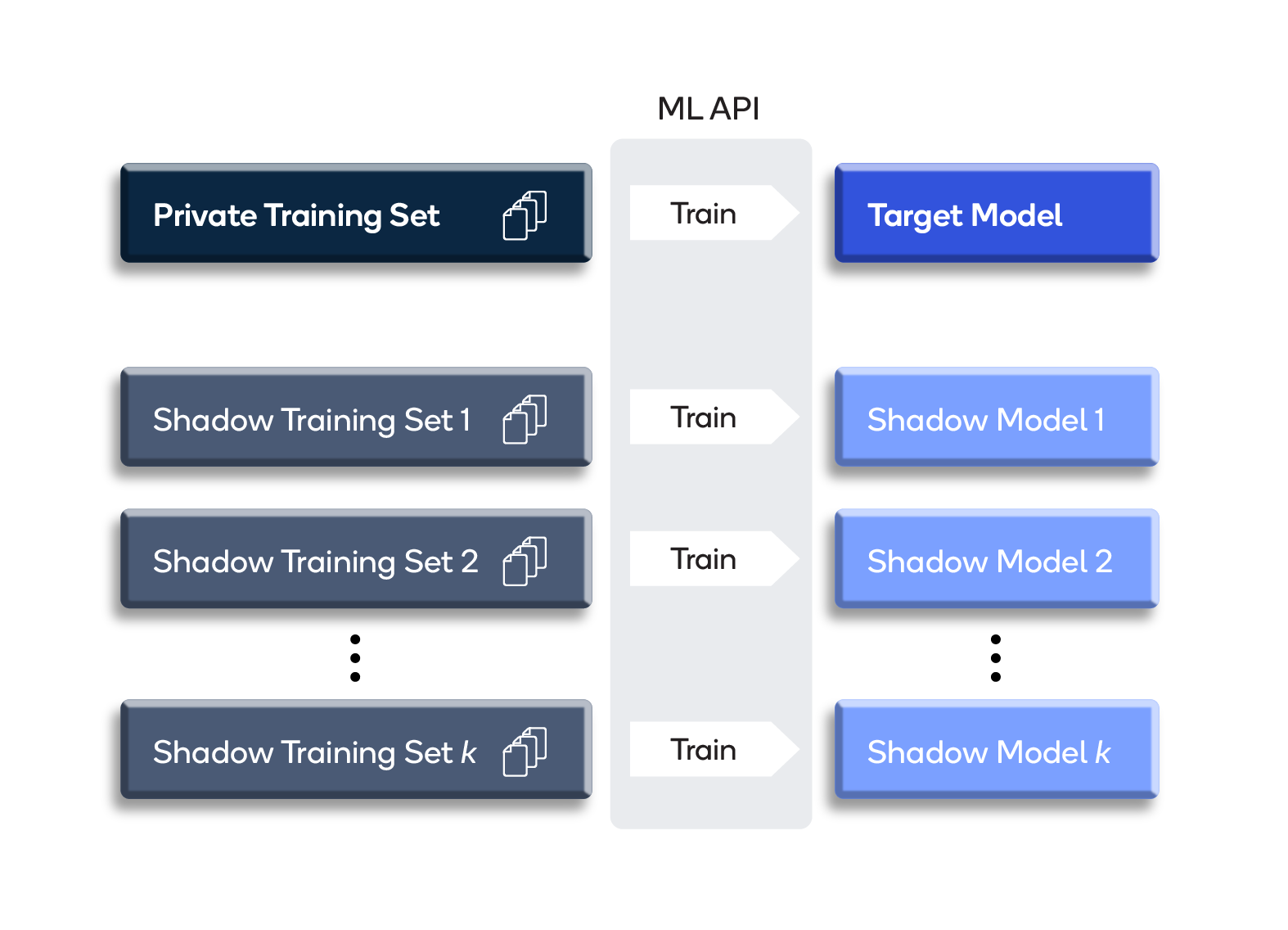
图 1 - 不同数据集上影子模型的并行训练的视觉描述。每个模型都是成为新生产模型的潜在候选者。
为了更好地理解这些不同级别的 MLOps 如何以及何时可以实施,考虑以下示例。
示例 1: 包装机器人
一个简单的例子是一个位于装配线末端的机器人,使用由 ML 驱动的计算机视觉来分析和包装产品。ML 模型可能已经被训练来识别有限范围内的方形和矩形箱子。然而,业务现在将引入新的形状和尺寸的包装,因此创建并部署了一个新的 ML 模型。在这种情况下,MLOps 级别 0 的开发团队将手动创建、训练和部署一个新模型,预防性地在新类型的包装开始在装配线上滚动之前。鉴于机器人的能力范围有限,这一层级的 MLOps 可能足够。
示例 2:语音识别
设想一个能够根据人们的说话方式感知或识别上下文(例如语调或情感)的移动应用。随着时间的推移,新短语和俚语出现,人们的说话风格也会发生变化。在这种情况下,机器学习模型可能会在较长时间内表现出模型衰退。
这是一个 MLOps 1 级指南可能有所帮助的示例。在 MLOps 1 级下,系统可以在设备上运行,监控模型的预测性能。如果性能接近或低于某个阈值,系统会触发警报,通知团队应使用新数据训练一个新模型,然后将其部署以替代生产模型。
示例 3:股票市场中的突发异常值
今年早些时候,石油价格进入了负值区域。如果一个机器学习模型是基于石油价格进行预测的,但只用正值价格进行训练,那么当它突然遇到负股票价格时会表现如何?在这种情况下,团队成员需要立即被警告,并且必须能够迅速训练和重新部署一个新的模型。
在这里,MLOps 2 级的实现可能会有所帮助。在这一层级,训练和部署新模型的流程大部分已被自动化,因此数据科学家应该能够处理大部分或所有的流程而无需开发人员的帮助。此外,自动化的程度应该使他们能够尽可能快速且可靠地更新、训练和部署新的模型。
为边缘设备实现 MLOps
许多现代高端边缘设备在 MLOps 方面表现优异。它们不仅能够托管大型模型,而且通常配备了专门优化推理运行的向量处理器。例如,Hexagon 数字信号处理器(DSP)就是 Qualcomm® Snapdragon™ 移动平台系列中的一员,它 为许多现代高端设备提供动力²。此外,这些处理器通常配备丰富的人工智能(AI)SDK 和工具集,开发人员可以利用这些工具优化和加载模型到设备上。正是这些 SDK 和工具可以集成到 MLOps 流程中,以便简化模型部署过程。
在机器学习工作流程的背景下,使用 SDK 的一般过程如下:
-
机器学习模型使用像 TensorFlow 这样的框架进行设计和训练。
-
Qualcomm Neural Processing SDK 中的转换工具用于将该模型转换为专有格式,优化以在 Snapdragon 上执行。
-
从 Qualcomm 神经处理 SDK 的 API 调用被添加到应用程序中,以将数据加载到 Qualcomm® Hexagon™ 处理器并进行推理。
-
一旦加载完成且应用程序运行,模型已被部署到边缘进行真实数据的推理。

图 2 - 在边缘设备上集成和执行 ML 模型的基本工作流。
在 MLOps 的背景下,上述的第 1、2 和 4 步骤会在产品生命周期内重复进行,因为需要进行模型更新。根据实施的 MLOps 级别,开发人员可能会构建额外的实体,如运行在边缘设备上的监控工具,以评估模型的预测性能。他们也可能构建某种警报和/或触发器,以启动 ML 工作流的新迭代。
深入了解 MLOps 管道
进一步来看,有许多工具和阶段需要集成到 MLOps 管道模型部署脚本中。以下展示了一个基于 Qualcomm 神经处理 SDK 的示例管道:
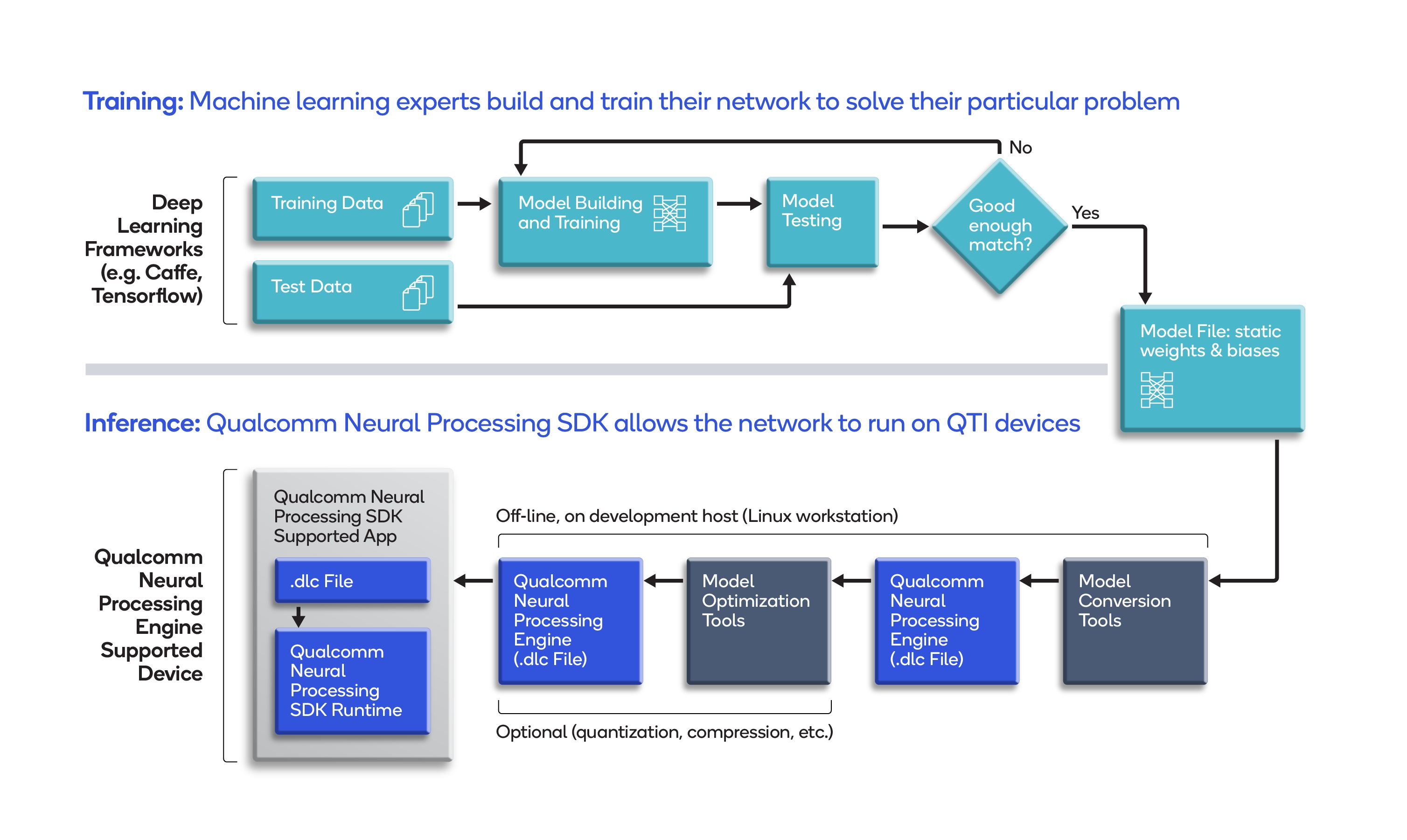
图 3 – 边缘设备 SDK 在 ML 工作流中的作用的更详细视图。
在工作流的上半部分,ML 模型在 ML 框架中进行训练。在工作流的下半部分,SDK 的工具被用来将模型转换为边缘设备的专有格式,并可选择地优化模型以适应边缘设备。在 MLOps 的背景下,这些工具要么是手动调用,要么是自动构建脚本的一部分。
开发人员还可以实施不同的方法将新模型重新加载到运行在边缘设备上的应用程序中。一个方法是在设备上运行服务,自动下载新模型并重新启动应用程序(甚至重新启动整个设备),但这可能会在重新启动过程中中断服务。另一种选择是应用程序本身在运行时监视新模型文件的存在,并重新调用必要的 API 来加载新模型。还有一种选择是使用推送方法,其中服务器发起的空中更新将新模型推送到设备。
根据应用程序的架构,每个选项可能会导致不同程度的停机,因为模型被部署并且应用程序切换到使用它。因此,开发人员需要权衡每种技术的实施复杂性与部署新模型所需的潜在停机时间。
结论
ML 系统本质上不同于传统软件,因为它们是非确定性的,并且在不断变化的数据世界中运行。但多亏了像 MLOps 这样的正式方法论,开发人员拥有了策划和实施稳健 ML 解决方案所需的工具。
随着机器学习在今天许多设备上的边缘计算中越来越重要,看到这些硬件与其 SDK 和工具结合能够支持有效的 MLOps 管道令人兴奋。
-
生产模型 指的是已经部署用于真实数据推断的机器学习模型。
-
www.statista.com/statistics/233415/global-market-share-of-applications-processor-suppliers/
简介:费利克斯·鲍姆 负责管理高通技术公司的数字信号处理器(DSP)软件产品,并在支持 Hexagon DSP 在连接、音频、语音、传感器融合、计算机视觉和机器学习应用中的作用中发挥了重要作用。
原文 已获授权转载。
相关:
-
驾驭 MLOps 中的复杂性
-
揭开 AI 基础设施堆栈的面纱
-
端到端机器学习平台巡礼