{kind=link}
{kind=link}
{kind=link}
{kind=link}
As instituições financeiras como bancos, financeiras, fintechs, operadoras de cartão de crédito, administradoras de consórcios tem uma necessidade em comum: Medir o “risco” de um cliente para uma operação de crédito, ou seja, medir o potencial de inadimplência diante do reembolso do dinheiro emprestado. Esta pontuação normalmente é chamada de “Credit Score”, que, dependendo da instituição, poderá ser uma porcentagem ou uma classificação numérica ou qualitativa como por exemplo:
Voce possui 975 pontos de score
- baixíssimo,
- baixo,
- médio,
- alto,
- altíssimo.
Voce foi classificado como risco baixo.
Este score, ainda, dependendo de políticas de crédito da instituição, definirá se o cliente vai obter o crédito e a qual taxa de juros a operação poderá ser ofertada. Devido ao grande volume de dados normalmente utilizados por estas instituições financeiras, a análise individual e manual de cada processo de concessão de crédito torna-se inviável. A utilização de ferramentas de inteligência artificial, como este trabalho pretende demonstrar, possibilita a análise automatizada dos dados sugerindo uma classificação ou uma probabilidade a inadimplência.
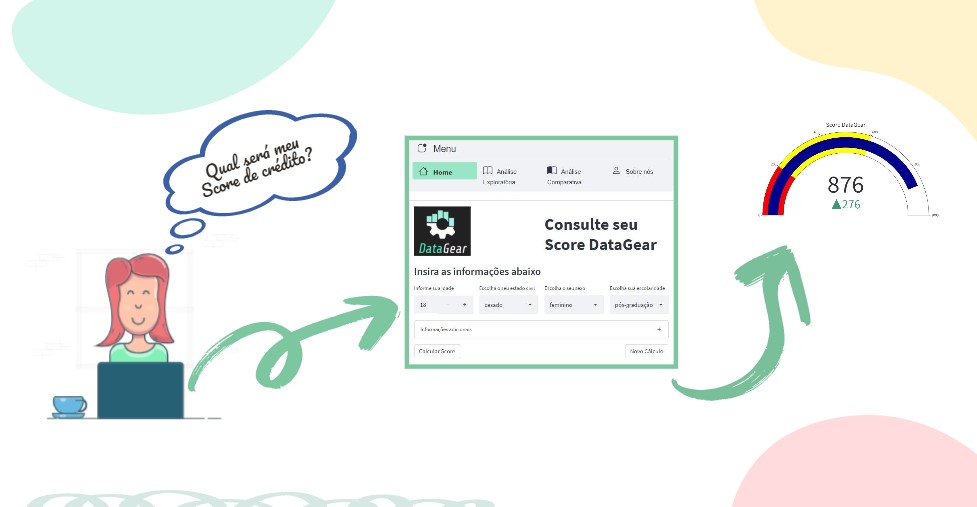
O principal objetivo e treinar um modelo capaz de prever a inadimplência, que dependerá de encontrar uma base de dados com exemplos suficientes, entender os dados e o negócio, efetuar a analise exploratória dos dados, treinar e e escolher o modelo através de métricas, desenvolver uma aplicação onde inferências possam ser calculadas com dados novos.
- Buscar uma base com dados suficientes.
- Analisar se esta base é compatível com o problema proposto.
- Workshop com especialista de domínio.
- Identificar as variáveis.
- Criar um dicionário de dados.
- Corrigir tipos de dados e traduzir nomes.
- Identificar e corrigir valores nulos e ou faltantes.
- Identificar e corrigir linhas duplicadas.
- Classificar as as variáveis.
- Criação de Gráficos.
- Definir o predito e os preditores.
- Verificar se os dados estão balanceados.
- Testar modelos.
- Escolher as métricas aplicáveis ao caso em estudo.
- Comparar os resultados.
- Escolher o melhor modelo.
- Serializar a sulução.
- Procurar uma forma de fornecer o cálculo para um cliente.
- Preparar página som Stremlit.
- Utilizar Docker para conteinerizar a aplicação.
- Publicar no Heroku.
- 01 - Analise expliratoria.ipynb
- Carga dos dados
- Correções dos dados
- Análise gráfica
- 02 - Comparative analysis.ipynb
- Correlações
- Pré-processamento
- Redução de dimensionalidade
- Tratamento para dados faltantes
- Grid Search
- Escolha do melhor modelo
- Treino do melhor modelo
- Serialização
- dicionario_dados.csv
- Descrição detalhada dos dados e qualificação das variáveis em numéricas e categóricas.
Para replicar o projeto recomendamos fortemente a utilização do Poetry, informações e instruções de instalação no link Poetry.
Após a instalação e a clonagem deste projeto e dentro da pasta do projeto deve ser efetuado o comando para instalar as dependências.
poetry install
Para ativar o virtual environment:
poetry shell
Pronto agora é só rodar:
Jupyter lab
| Dependências | Versão |
|---|---|
| python | 3.8 |
| numpy | 1.22.3 |
| pandas | 1.4.2 |
| jupyterlab | 3.3.4 |
| scikit-learn | 1.0.2 |
| seaborn | 0.11.2 |
| matplotlib | 3.5.1 |
| pandas-profiling | 3.2.0 |
| xlrd | 2.0.1 |
| xgboost | 1.6.1 |
| streamlit | 1.10.0 |
| plotly | 5.9.0 |
| streamlit-option-menu | 0.3.2 |
 Brena Rodrigues |
 Matheus Fanali Giraldes |
 Rian Araújo dos Santos |
 Rodolfo Autran |
 Vilquer de Oliveira |
|---|
├── data # Diretório contendo todos os arquivos de dados (Geralmente está no git ignore ou git LFS)
│ ├── external # Arquivos de dados de fontes externas
│ ├── interim
│ ├── processed # Arquivos de dados processados
│ └── raw # Arquivos de dados originais, imutáveis
├── docs # Documentação gerada através de bibliotecas MKDocs
├── models # Modelos treinados e serializados, predições ou resumos de modelos
├── notebooks # Diretório contendo todos os notebooks utilizados nos passos
├── references # Dicionários de dados, manuais e todo o material exploratório
├── src # Código fonte utilizado nesse projeto
│ ├── data # Classes e funções utilizadas para download e processamento de dados
│ ├── deployment # Classes e funções utilizadas para implantação do modelo
│ ├── model # Classes e funções utilizadas para modelagem
├── README.md # Informações gerais do projeto
├── mkdocs.yml
├── poetry.lock # Arquivo com subdependências do projeto principal
├── pyproject.toml # Arquivo de dependências para reprodução do projeto
├── tasks.py # Arquivo com funções para criação de tarefas utilizadas pelo invoke
